오늘은 최근에 중국 Baidu에서 나온 PDFTranslate를 활용하여 FastAPI를 구현했습니다.
PDFMathTranslate는 (수학) 논문 PDF를 번역하고, 원본 문서와 번역된 문서를 비교할 수 있는 기능을 제공합니다. 특히 수식, 차트, 목차, 주석 등 원본의 구조를 유지하면서 번역 결과를 제공하고 있어 수학 분야를 비롯한 자연 과학 분야의 논문들을 번역하기에 좋습니다. 다양한 언어 및 외부 번역 서비스 등을 지원하며, 명령줄 도구, GUI, Docker 환경 등 다양한 방식으로 활용할 수 있습니다.
pdfTranslate의 주요 특징으로는 아래와 같습니다.
- 구조 보존: 수식, 차트, 목차 등의 구조를 손실 없이 번역
- 다양한 번역 서비스 지원: Google Translate 및 DeepL 등과 호환
- 다양한 사용 방식: 명령줄(CLI)에서 간편하게 실행 가능하며, GUI를 통해 브라우저 기반으로도 활용 가능
- 고급 옵션 제공: 부분 번역, 멀티 스레드 지원 및 사용자 정의 번역 프롬프트 추가 등
참조한 Github은 아래와 같습니다.
공식 Github : https://github.com/Byaidu/PDFMathTranslate
1. 필요한 패키지 설치하기 및 Docker 설정
어려운 부분이 아니니 추가 설명은 하지 않겠습니다. Conda나 venv와 같은 가상환경에서 하시는 것은 자유입니다.
# pip 설치
pip install pdf2zh
# Docker 불러오기
docker pull byaidu/pdf2zh
2. app.py 생성
코드 추가입니다. API는 하나로만 구성되어있고 pdf 번역하는 API입니다. 매우 간단하고 다른 글들에 비해서 코드가 짧습니다. 이해하기가 편하실껍니다.
아래 코드에서 input_pdf_path와 output_pdf_path는 실행하는 서버에
import os
import subprocess
from fastapi import FastAPI, File, UploadFile, Form
from fastapi.responses import FileResponse
app = FastAPI()
AVAILABLE_LANGS = ["en", "zh", "ko", "ja"]
@app.post("/translate_pdf/")
async def translate_pdf(
file: UploadFile = File(...),
source_lang: str = Form(..., description="Original PDF language (en, zh, ko, ja)"),
target_lang: str = Form(..., description="Target PDF language (en, zh, ko, ja)"),
target_page: str = Form(..., description="Target PDF page (1-3, 5, all, ...)"),
):
if source_lang not in AVAILABLE_LANGS or target_lang not in AVAILABLE_LANGS:
return {"error": "Invalid language selection. Choose from en, zh, ko, ja."}
input_pdf_path = f"/workspace/PDFtranslate/{file.filename}"
filename_without_ext, ext = os.path.splitext(file.filename)
output_pdf_path = f"/workspace/PDFtranslate/{filename_without_ext}-mono{ext}"
with open(input_pdf_path, "wb") as buffer:
buffer.write(await file.read())
if target_page == "all":
command = ["pdf2zh", input_pdf_path, "-li", source_lang, "-lo", target_lang, "-t", "4"]
else:
command = ["pdf2zh", input_pdf_path, "-li", source_lang, "-lo", target_lang, "-t", "4", "-p", target_page]
subprocess.run(command, check=True)
return FileResponse(output_pdf_path, filename=f"output_pdf_path", media_type="application/pdf")
3. 실행 및 결과 확인
실행하는 방법은 아래 커맨드를 입력해주시면 됩니다. 그러면 웹에서 localhost:4444에 접근을 할 수 있게 됩니다. 근데 이 화면은 아무 UI가 없으니 확인하려면 Swagger로 확인해보시는 게 좋습니다.
uvicorn, FastAPI와 같은 라이브러리는 따로 설치를 하셔야합니다.
! uvicorn app:app --host 0.0.0.0 --port 4444 # port는 자유
그래서 localhost:4444/docs로 접근해보죠. 그러면 아래와 같은 화면이 뜨게 됩니다.

어떻게 사용하는 지 알려드리겠습니다.
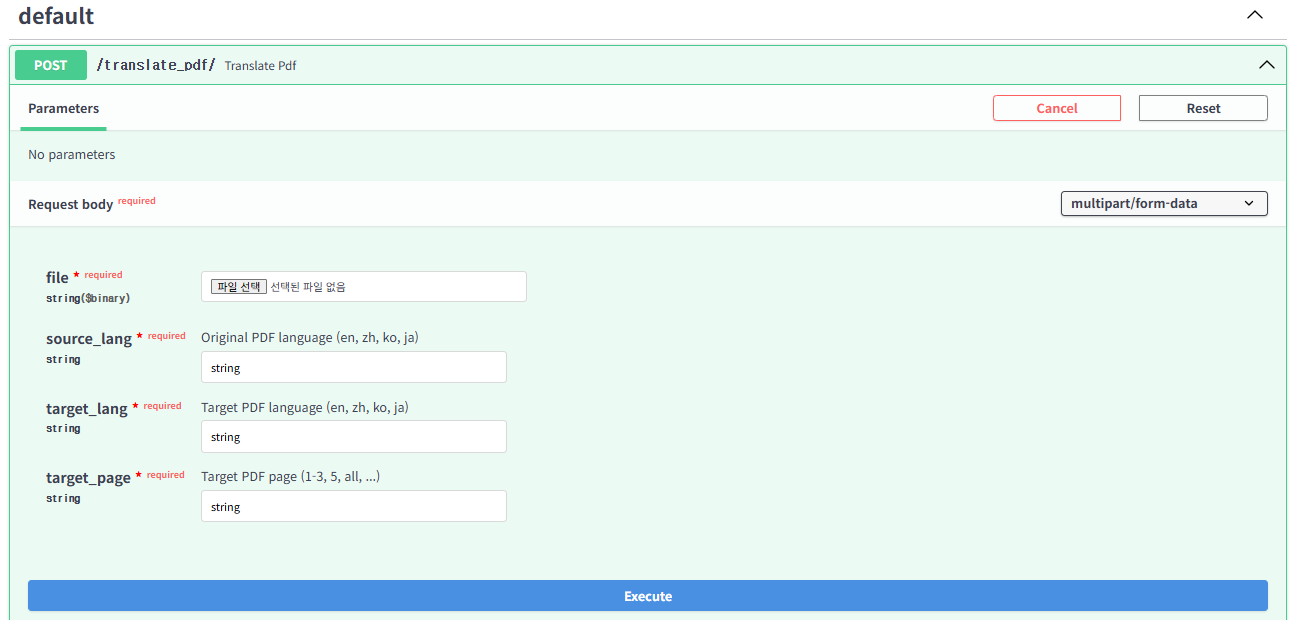
우측의 화살표를 누르고 "Try it out" 버튼을 누르면 아래와 같은 화면이 나오는데 여기서 file에 pdf를 업로드 하시고 Execute를 누르면 됩니다.
source_lang은 pdf의 언어가 어떻게 되어있는 지 작성하면 되고 target_lang은 번역하고자 하는 언어를 입력하시면 됩니다. target_page는 몇 번째 페이지만 번역할 지 선택하시면 됩니다. all을 하시거나 1-3번째 페이지만 번역할 수 있습니다.
(en : 영어, zh : 중국어, ko : 한국어, ja : 일본어, ... 타 언어는 공식 Github에서 참고하시면 됩니다.)
실행을 하면 아래처럼 download file이 나오게 되고 클릭해서 다운받으시고 비교하시면 됩니다.

하지만 번역이 완벽하지는 않습니다. 아래에서 보시면 직독직해 수준이긴 합니다. 그래도 수식 레이아웃, 글자 레이아웃을 완벽하게 보존하면서 번역을 한다는게 정말 대단한 기술인 것 같습니다. 추후 PDFTranslate 버전이 업그레이드되고 더 번역 수준이 높아진다면 논문을 쉽게 읽을 수 있을 수도 있고 이 API를 잘 활용하여 솔루션을 만들수도 있을 것이라 기대합니다.

궁금하신 사항 있으시면 언제든 댓글로 의견 주시면 감사하겠습니다.
'Machine Learning' 카테고리의 다른 글
| Stable Diffusion FastAPI 구현 (0) | 2025.02.03 |
|---|---|
| Grounding-DINO FastAPI 구현 (1) | 2024.12.06 |
| GLIP : Grounded Language-Image Pre-training (1) | 2024.07.26 |
| CNN 기반 모델들 (0) | 2024.06.25 |
| 딥러닝 기초 지식 (2) | 2024.06.11 |