이번글에는 NAVER Clova 팀에서 발표한 DEER: Detection-agnostic End-to-End Recognizer for Scene Text Spotting 라는 모델에 대해 정리해봤습니다.
DETR을 기반으로한 모델이며, Deformable DETR을 보고 오시면 더 이해가 빠릅니다.
학습 코드가 공개되어 있지 않기 때문에 모델 사용을 위해선 직접 구현해야 합니다.
Introduction
일반적인 end-to-end text spotting 파이프라인은 text detector와 recogntion으로 구성됩니다. Text detector는 이미지내의 텍스트 위치를 Box 또는 Polygon 모양의 결과를 출력하고, Recognition은 detector로 부터 출력된 결과를 입력으로 사용하여 이미지내의 문자를 인식합니다.

이전의 Scene text spotting 파이프라인은 위에 언급한 내용처럼 Detector와 Recognizer를 결합하여 사용했습니다. 특히, Dector의 결과로 Crop한 이미지를 Recognizer의 입력으로 사용하는 경우, Recognition 성능은 Detector에 심하게 의존할 수 밖에 없는 구조(위 그림에서 확인 가능합니다.)입니다.
최근에는, End-to-end text spotting methods들이 제안 되었는데, ROI poling이나 Masking으로 Features를 추출하고, Recognizer의 입력이 단일 단어가 되도록 수정하면서 Detector와 Recognizer의 결합(coupled)정도(모델의 성능이 서로에게 영향을 미치는 정도)를 낮췄습니다.
Object detection 분야에서 End-to-End Transformer 기반의 접근 방식이 연구됨에 따라, 정교한 GT나 Feature pooling등의 방식이 덜 중요하게 되고 있다. 이에 저자들은 Detector에 의존하지 않은 DEER라는 Transformer based의 End-to-end recognizer 모델을 제안했습니다.
DEER는 정확한 Text regions를 검출하는 것 대신에 각 텍스트에 Single reference point를 인식하도록 합니다.
저자들은 DEER가 Single reference point만 찾도록 요구되므로, 다양한 Detection 알고리즘과 Annotations를 사용할 수 있으며, 이 접근 방식은 회전 되거나 굴곡진 텍스트를 Pooling 작업이나 Polygon-type의 Annotations 없이 다룰 수 있다고 주장합니다.
Related Works
관련 연구에는 제안 모델의 기반인 DETR에 대해서만 정리를 진행했습니다.
DETR은 Spatial anchor-boxes 나 Non-maximum suppression 등의 정교한 수작업이 필요한 과정 없이 경쟁적인 성능을 보였습니다.
Deformable DETR은 Deformable attention을 적용함으로써 DETR의 느린 학습속도를 보완했고, Multi-scale features를 사용해서 Small objects 검출 성능을 향상 시켰습니다.
Efficient DETR은 Reference point와 Object queries를 잘 초기화 시켜서 학습 속도를 더 가속화 했습니다.
이러한 연구들은 높은 인식 성능을 달성하기 위해 좋은 검출 성능이 필요하지 않다는 것을 보여줍니다.
위의 연구들을 기반으로, 저자들은 Transformer 구조와 Reference points를 이용한 컨셉이 좋은 성능을 보일 것이라고 예상한 듯 합니다.
DEER
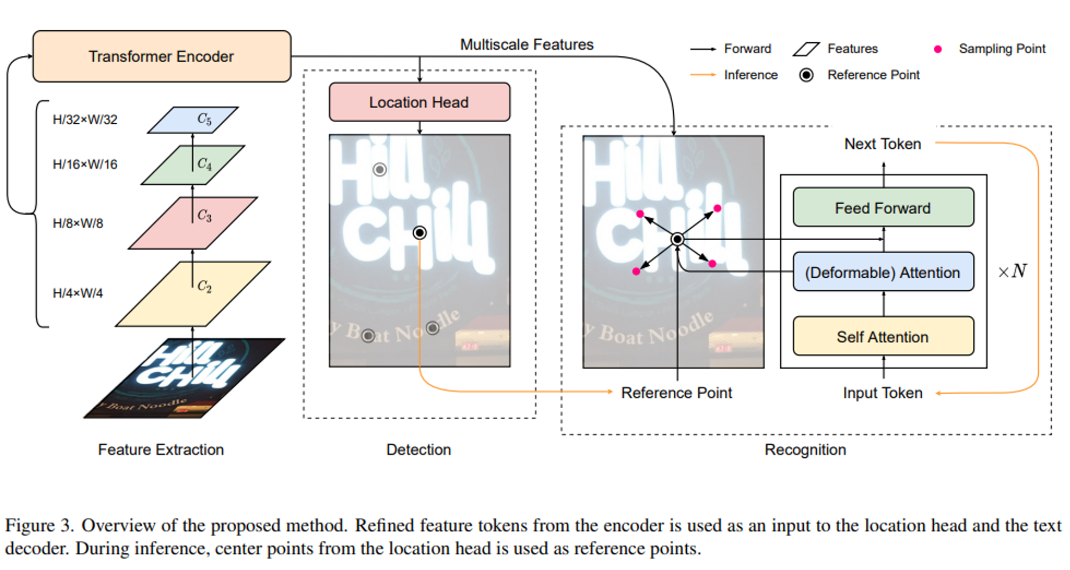
DEER는 Backbone, Transformer encoder, Location head, Text decoder로 이루어져 있으며, 전체적인 파이프라인은 위 그림과 같습니다. 먼저, Transformer encoder는 Multi-scale feature maps를 백본으로 부터 결합(Combine)합니다. 그 후, Location head는 텍스트의 Reference point를 예측하고, (필요하다면) Bounding boxes도 같이 예측합니다. 마지막으로, Text decoder는 Reference point를 이용하여 글자들을 생성해 나갑니다.
Forward 단계에서 Input image는 $X \in R^{H \times W \times 3}$의 형태로 Backbone에 입력되고, $C_2, C_3, C_4, C_5$의 Feature maps를 추출합니다. 각 Feature maps의 Resolution은 원본 이미지 크기의 1/4, 1/8, 1/16, 1/32 입니다. 그 후, fully-connected layer와 group normalization을 적용하여 256 Channels이 되도록 합니다. 그리고 Flatten 과 Concatenate를 이용하는데, Feature token의 크기는 $(L_2 + L_3 + L_4 +L_5) \times 256$이 되며, $L_i$는 $C_i$의 길이 입니다. 이렇게 변환한 값을 Transformer Encoder의 Input으로 사용합니다.
Location head에는 $L_2$ 에 해당하는 Feature map을 사용했습니다.
작은 글씨도 검출해내기 위해 비교적 고해상도의 Feature map을 사용한 듯 합니다.
Location Head
Pnoptic segformer과 Efficient detr의 접근법에 영감을 받아, 저자들은 Location head를 사용하여 Text decoder에 필요한 Reference point(텍스트의 중심 위치)를 예측했습니다. 추가적으로, 텍스트의 Polygon을 추출하기 위한 Segmentation map도 제공하는데, 이는 모델 평가를 위해서 입니다.
$L_2$에 Segementation head를 이용하여 Segmentation map을 얻는데, Segmentation head는 Transpose Conv, Group norm과 ReLU로 구성되어 있습니다.
Text Decoder
Text decoder에 대한 Query $Q$는 Character embedding, Positional embedding과 Reference point $q_{ref}$로 구성되어 있습니다. Text decoder의 Key $K$와 Value $V$는 Transformer encoder에서 계산한 Feature token $F$입니다. 저자들은 Self-attention, Deformable Attention과 Feed-forward layer를 통해 query를 전달합니다. 또한 저자들은 Pnoptic segformer과 An empirical study of spatial attention mechanisms in deep networks 에서 영감을 받아, $F$를 계산할 때, Deformable attention 대신 Regular cross attention을 추가합니다.
훈련 중에 $N_t$개의 텍스트 상자가 이미지에서 샘플링되고, 계산되어 있는 중심 좌표가 Decoder의 Reference points로 사용됩니다. 이것은 Location head와 Text decoder의 학습을 독립적으로 수행할 수 있도록 합니다. 학습 과정에는 GT로 부터 계산한 중심 좌표를 사용하고, 평가 과정에서는 Detection branch에서 생성한 Reference point가 사용됩니다. GT로 부터 계산한 좌표값(학습 과정)과 모델이 예측한 좌표값(평가 과정)의 차이(편차)를 줄이기 위해 학습 과정에서 GT 좌표값에 노이즈(Perturbed)를 추가합니다.
$$ q_{ref} = p_c +\frac{\eta}{2}min(||p_{tl}-p_{tr}||, ||p_{tl}-p_{bl}||), \\
\eta \sim Uniform(-1,1) $$
$p_c$는 GT Polygon의 중심값을 의미하고, $p_{tl},p_{tr},p_{bl}$ 은 top-left, top-right와 bottom-left point를 의미합니다.
Optimization
$$ L =L_r+\lambda_sL_s+\lambda_bL_b+\lambda_tL_t $$
학습에 사용하는 Loss는 위 식과 같습니다. $L_r$은 Text recognition loss이며, $L_s,L_b,L_t$는 이진화 근사함수(Differentiable binarization)로 부터 얻은 Loss입니다. 조금 더 자세하게 설명하면, $L_r$은 softmax cross entropy로 계산하는데, GT Text label과 Decoder가 예측한 글자와의 차이를 의미합니다. 이진화 근사함수는 Real-time scene text spotting with adaptive bezier-curve network 에서 제안된 방법론인데, $L_s$는 이를 적용하여 Hard negative mining한 결과에 binary cross entropy를 통해 Loss를 구합니다. $L_b$에는 Dice loss를 적용했으며, $L_t$는 $L_1$ Distance loss를 사용합니다.
추론 단계에서는 Location head에서 얻은 Probability map만을 사용합니다. Probability map은 지정된 임계값을 통해 이진화 되고, 이진 맵에서 연결된 구성 요소가 추출됩니다. 추출된 영역의 크기는 실제 텍스트 영역보다 작으므로, Vatti clipping 알고리즘을 통해 실제 크기로 확장됩니다. 이를 통해 Polygon region을 추출하고, 중심점을 찾아 Text decoder의 reference point로 사용합니다.
Implementation details
데이터셋으로는 TextOCR, ICDAR 2015, TotalText를 사용했습니다.
모델은 TextOCR 데이터셋을 이용하여 10k warmup steps를 거치고 400k steps 만큼 사전 학습을 진행합니다. 이 과정에서 Adam optimizer와 Consine learning rate schedular가 사용됩니다. Pretaining 중에 Learning rate는 3e-4로 설정되었고, Weight decay는 1e-6으로 설정했습니다. 그 후, 각 벤치마크 데이터셋에 대해 10k steps 만큼 Fine-tune을 진행하는데, Learning rate는 5e-5를 사용했습니다. Batch size는 32로 설정했고, 샘플의 각 이미지에는 2개의 텍스트가 포함되어 있습니다.
데이터 증강에는 -90 ~ 90도의 Random rotation과 50% ~ 300%의 Random resize, Bounding Box가 보존되는 Safe random crop up to 640 pixels, 0.8 확률의 color jitter를 사용합니다. 추론 과정에는 크기 비율을 유지하여 1280 이나 1920 pixels의 resized된 이미지를 사용합니다.
마치며
모델의 테스트 결과와 Ablation study에 대한 내용은 따로 정리하지 않았습니다.
그동안 DETR에 대해 꾸준히 공부하고 정리해오고 있는데, OCR 분야에도 적용한 논문이 있기에 먼저 논문을 읽어봤습니다.
추후에 직접 구현 및 테스트까지 시도를 해볼듯 합니다.
저자분들이 정리하신 내용은 여기 에서 더 자세히 확인해 보실 수 있습니다.
'Machine Learning > Image' 카테고리의 다른 글
| Panoptic SegFormer (0) | 2024.10.07 |
|---|---|
| Conditional-DETR : for Fast Training Convergence (1) | 2024.09.25 |
| Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection (0) | 2024.07.12 |
| DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR (1) | 2024.07.05 |
| DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection (0) | 2024.07.04 |