오늘은 Conditinal-DETR이라는 논문에 대해서 리뷰하겠습니다.
해당 논문은 헝가리안 알고리즘에 대한 기초 지식을 알고 있다는 전제하에 작성한 글입니다. 따로 헝가리안 알고리즘에 대해 정리하겠지만 미리 공부하고 보면 더 도움이 될 것입니다.
그리고 이전에 작성했던 DAB-DETR, DN-DETR, Deformable-DETR의 기초가 되는 논문이니 그 전에 읽어보시는 것을 권장합니다.
세부적인 내용들은 찾아보시는 걸 권장하고 틀린 부분이 있으면 언제든 댓글로 말씀해주시면 수정하겠습니다.
"Conditional DETR for Fast Training Convergence",
Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang (2023)
https://arxiv.org/abs/2108.06152
Abstract
이 논문에서는 DETR(DEtection TRansformer)의 성능을 향상시키기 위한 Conditional-DETR라는 새로운 모델을 제안합니다. 기존 DETR의 한계 중 하나는 훈련 시간이 길고, 수렴 속도가 느리다는 점입니다. 이를 해결하기 위해 Conditional-DETR은 조건부 크로스 어텐션(Conditional Cross-Atttention) 메커니즘을 도입하여, 각 예측된 바운딩 박스와 객체 쿼리 간의 상관 관계를 개선하고, 객체 탐지 성능을 높이면서도 훈련 효율성을 극대화하는 방법을 제시합니다.
Introduction
본 논문에서는 Conditional-DETR라는 새로운 객체 탐지 모델을 제안하며, 기존의 DETR 모델이 가진 문제점을 해결하고자 합니다. DETR은 혁신적인 Transformer 구조를 활용하여 객체 탐지 문제를 해결하지만, 느린 훈련 속도와 수렴 속도의 문제가 지적되어 왔습니다. 기존 DETR 모델은 특히 바운딩 박스 예측에 있어서, 각 객체 쿼리와 실제 객체 간의 상관 관계를 충분히 잘 반영하지 못하여 비효율적인 매칭을 유발하고, 이로 인해 훈련 과정에서 많은 시간이 소요됩니다.
기존 DETR은 약 500 Epoch이 진행되어야 수렴이 되는데, 느린 이유는 아래와 같이 설명할 수 있습니다.
- 기존 DETR 학습 주된 매커니즘
- Object Query들의 임베딩이 Encoder와 Cross-Attention으로 학습이 이루어지면서, 이미지와 관련된 Features를 학습 ( = 이걸 Content Embedding이라 함)
- 문제는 Content Embedding에 너무 의존함
- 이게 적게 돌면 성능 저하
- 또한, Position Embedding을 빼면 성능이 크게 저하하는 이슈도 있음
- 객체에 대한 공간 정보에 대한 필요성 증가
Conditional-DETR은 이러한 문제점을 해결하기 위해 Conditional Cross-Attention 메커니즘을 도입합니다. 이 메커니즘은 객체 쿼리가 보다 효과적으로 바운딩 박스를 예측할 수 있도록, 바운딩 박스의 위치와 객체 특성을 조건으로 하는 새로운 Attention 방법을 사용합니다. 이를 통해 각 쿼리가 보다 명확한 공간적 정보를 얻어, 객체 탐지의 정확성과 훈련 속도를 동시에 향상시킵니다.
객체 공간(위치)을 학습할 수 있는 Embdding을 만들어서(즉, Condition) , 이 Content Embedding과 따로 학습시키고, Decoder Layer 중간 중간에 적절하게 주입합니다.

이 논문의 주요 기여는 다음과 같습니다.
첫째, 기존 DETR의 느린 수렴 문제를 해결하기 위한 새로운 방법론을 제시합니다.
둘째, Conditional Attention을 통해 객체 탐지 과정에서의 쿼리와 바운딩 박스 간의 연관성을 개선합니다.
셋째, Conditional-DETR은 효율적인 training 과정을 통해, 기존의 CNN 기반 객체 탐지 모델과 Transformer 기반 모델 사이의 성능 격차를 좁히며, 실용적인 응용 가능성을 높입니다.
따라서, Conditional-DETR은 DETR의 혁신적인 아이디어를 유지하면서도 훈련 속도와 성능 면에서 크게 개선된 모델로, 실제 애플리케이션에서 더욱 효율적인 객체 탐지를 가능하게 합니다.
Conditional-DETR

아키텍처의 전체적인 형태에 대해서 설명드리겠습니다.
Conditional-DETR의 아키텍처는 크게 backbone, transformer encoder, transformer decoder로 구성됩니다.
먼저 backbone에서 입력 이미지를 처리하여 이미지 피처 맵을 추출합니다. 이 피처 맵은 모델의 나머지 부분에서 사용될 기본 정보로 사용됩니다.
이후 Encoder는 이미지를 처리한 피처 맵을 입력으로 받아 여러 층의 self-attention 메커니즘을 통해 정보를 추출합니다.
Encoder는 피처 맵 내에서 모든 위치 간의 상관 관계를 학습하여 전역적인 문맥 정보를 강화합니다.
Conditional-DETR의 핵심은 Transformer Decoder 부분에 있습니다.
기존 DETR과 달리, Conditional-DETR의 Conditional Cross-Attention은 각 객체 쿼리가 특정 바운딩 박스 정보를 기반으로 attention을 수행하게끔 설계되어 있습니다. 이 방식은 각 쿼리가 단순히 이미지 전체에 대해 attention을 수행하는 대신, 보다 정확한 위치 정보에 따라 바운딩 박스를 예측하게 하여 훈련 효율성을 높입니다.
Decoder는 바운딩 박스 좌표와 객체 분류 결과를 출력으로 내보냅니다. 이 디코더 출력은 각 쿼리마다 이미지의 객체 위치와 그에 해당하는 class label을 함께 예측하게 됩니다.
단계를 요약하면, Backbone은 이미지를 피처 맵으로 변환하고, Encoder는 이 피처 맵의 정보를 풍부하게 만듭니다. 이후 Decoder는 Conditional Cross-Attention을 통해 객체와 바운딩 박스를 효과적으로 매칭하여 최종적으로 객체 위치와 label을 출력하게 됩니다.
수식으로도 간단하게 설명드리겠습니다.
먼저 바운딩 박스를 어떻게 예측하는 지 살펴보겠습니다.
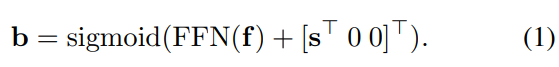
- f는 객체의 특징(=Content Embedding)을 담은 feature vector
- FFN(f)는 feature vector 에서 바운딩 박스의 좌표를 예측하는 regression 함수
- s는 바운딩 박스의 조건부 공간적 정보(=Positional Embedding)
- 추가 정보 1) s가 (0,0)으로 고정되어있고 sigmoid취하면 (0.5,0.5)가 되어 reference point가 중앙임
- 추가 정보 2) Deformable DETR에서는 s가 고정된 값이 아님
- 더한 후 sigmoid 함수를 적용하여 바운딩 박스 좌표 b를 예측
그리고 가장 중요한 DETR에서 어떻게 Cross-Attention이 진행되는 지 살펴보겠습니다.

- cq: 객체 쿼리의 콘텐츠(content query), 객체 쿼리의 feature 정보를 가짐
- pq: 객체 쿼리의 위치(position query), 쿼리의 공간적 정보를 가짐
- ck: key에 해당하는 이미지의 콘텐츠(content key), 입력 이미지에서 추출된 피처 맵의 특정 위치에 대한 정보를 가짐
- pk: key에 해당하는 이미지의 위치(position key), 이미지 내에서 피처의 공간적 정보를 가짐
⊤는 내적을 의미합니다. 기존 DETR에서는 콘텐츠 정보와 위치 정보가 서로 혼합된 상태에서 상호작용을 수행합니다. 즉, 쿼리와 피처 간의 상호작용을 모든 차원에서 복합적으로 계산하게끔 되어 있습니다.
그러면 Conditional_DETR에서는 어떻게 동작할까요?

Conditional-DETR은 콘텐츠 정보와 위치 정보를 명확하게 분리하여, 각각의 상호작용을 따로 수행합니다. 이를 통해 더 효율적으로 바운딩 박스를 예측하고, 훈련 수렴 속도를 개선합니다.
즉, 정리하자면 DETR에서는 콘텐츠 정보와 위치 정보가 결합되어 상호작용하는 반면, Conditional-DETR에서는 콘텐츠와 위치 정보를 분리하여 각각 독립적으로 계산합니다.

위 그림에서 각 행은 Conditional-DETR이 객체를 탐지하는 과정에서 중요한 역할을 하는 Attention 메커니즘을 설명합니다.
첫 번째 행은 공간적 attention 맵으로, 이미지 내에서 객체가 위치할 가능성이 높은 영역을 나타냅니다. 자전거와 소 같은 객체의 외곽이나 테두리 부분에 attention이 집중되어 있으며, 이를 통해 모델이 객체의 공간적 위치를 예측하는 데 중점을 두고 있음을 알 수 있습니다. 이러한 공간적 attention은 객체의 정확한 위치를 추정하기 위해 바운딩 박스를 설정하는 중요한 정보로 사용됩니다.
두 번째 행은 콘텐츠 attention 맵을 보여줍니다. 이는 객체의 시각적 특징, 즉 모양이나 텍스처와 같은 정보에 집중하고 있습니다. 예를 들어, 자전거의 바퀴나 소의 얼굴 등 객체의 중요한 부분에 attention이 집중되어 있으며, 이는 객체가 무엇인지 인식하고 클래스(종류)를 결정하는 데 핵심적인 역할을 합니다.
세 번째 행은 공간적 attention, 콘텐츠 attention이 결합된 맵입니다. 두 가지 attention을 결합하여 객체의 위치와 특징 정보를 모두 반영하는 최종 attention 맵을 생성합니다. 이 결합된 attention맵에서는 자전거의 외곽이나 소의 몸통 부분처럼 객체의 경계나 중요한 부분에 attention이 집중되어 있습니다. 이를 통해 Conditional-DETR이 공간 정보와 콘텐츠 정보를 통합하여 더 정확하게 객체를 탐지하고 바운딩 박스를 생성하는 과정을 확인할 수 있습니다.
Experiments와 Conclusion은 실험 결과 및 토의 부분이기 때문에 따로 적지는 않았습니다.
'Machine Learning > Image' 카테고리의 다른 글
| Efficient DETR (1) | 2024.10.14 |
|---|---|
| Panoptic SegFormer (0) | 2024.10.07 |
| DEER: Detection-agnostic End-to-End Recognizer for Scene Text Spotting (4) | 2024.07.23 |
| Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection (0) | 2024.07.12 |
| DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR (1) | 2024.07.05 |