DEER 이론의 마지막 시리즈가 될 것 같습니다.
현재 학습을 진행중이고, 최대한 코드 정리를 해서 깃허브에 업로드 예정입니다.
그럼 바로 시작하겠습니다.
Yao, Zhuyu, et al. "Efficient detr: improving end-to-end object detector with dense prior."
arXiv preprint arXiv:2104.01318
(2021).
https://arxiv.org/pdf/2104.01318
Abstract
DETR 및 Deformable DETR과 같은 E2E Transformer detector는 6개의 Decoder Layer를 쌓아 Object Queries를 반복적으로 업데이트하는 구조를 갖고 있으며, 이 구조가 없으면 성능이 심각하게 저하됩니다. 저자들은 이 문제가 Object Queries와 Reference Point를 포함하는 Object Containers의 무작위 초기화를 원인으로 지목합니다. Efficient DETR은 간단하고 효율적인 구조를 갖게 하고, dense detection과 sparse set detection의 장점을 모두 활용하여 1개의 Decoder Layer를 사용하여, 6개의 Decoder Layer를 사용한 모델의 성능에 근접합니다.
Introduction
DETR / Deformable DETR은 6개의 Encoder와 6개의 Decoder로 이루어진 Transformer Architecture 입니다. 저자들은 이 구조에서 DETR 시리즈가 Object Detection 분야에서 좋은 성능을 내는 키 라고 가정합니다.
저자들은 광범위한 실험을 통해 추가적인 auxiliary loss가 있는 Decoder Layer가 성능에 가장 큰 영향을 미치는 것을 발견했습니다. 또한, DETR에서 Object Containers에 대한 무작위 초기화가 Decoder Layer를 많이 쌓아야하는 것에 대한 주요 원인이며 수렴을 느리게 한다는 것을 알아봅니다. 최종적으로 저자들은 Dense와 Sparse로 구성된 Efficient DETR을 제안합니다. 두 부분 모두 동일한 detection head를 공유합니다. Dense part에서는 슬라이딩 윈도우를 기반으로 하는 class spectific dense prediction으로 proposals를 생성합니다. 4차원 proposals에 대해 Top-K를 사용하고, 256-d encoder features를 Reference Point와 Object Queries로 사용합니다. 이 방법은 매우 합리적이여서 단 1개의 Decoder Layer만으로 더 나은 성능과 빠른 수렴을 달성했다고 합니다.
Exploring DETR

Table 1에서는 auxiliary loss가 모델의 성능에 미치는 영향을 파악하고자 하였고, Table 2는 cascade를 몇 번 진행하는지에 따른 모델의 성능을 보려고 했습니다. Table 2번에 따라, 어느정도 성능은 유지하면서 모델의 크기가 작은 Encoder Layer와 Decoder Layer 각각 3개를 가진 모델을 baseline으로 정하고 실험을 진행했습니다.
저자들은 Encoder 보다 Decoder가 중요하다 주장하는데, Encoder와 Decoder 모두 연속적인 구조를 갖지만, Decoder는 추가적인 auxiliary loss를 갖고 있고, DETR이 Decoder Layer 갯수에 예민한 원인이라고 말합니다. auxiliary loss 없이는 encoder와 decoder는 같은 양상을 보이고, auxiliary decoding loss가 query feature를 업데이트할 때 강력한 영향을 미침으로써 디코더를 더욱 효율적으로 만든다고 합니다.
Object queries는 최종 결과에 밀접한 관련이 있는데, 기존 DETR에서는 학습 시작 시 무작위로 초기화됩니다. 이 무작위 초기화는 좋은 시작점이 아니라고 가정하며, 이것이 DETR에서 높은 성능을 달성하기 위해 6개의 Decoder Layer가 필요한 이유일 수도 있다고 주장합니다.
Object queries의 initialization을 연구하는 것은 충분한 가치가 있지만, Object query는 학습 가능한 positional embedding으로 256-d의 tensor로 이루어져 있기 때문에 분석이 어렵다고 말합니다. 그러나 저자들은 DETR에서 Object query가 특정 영역과 box 크기를 배운다는 것을 확인했고, Deformable DETR은 Object query와 관련된 Reference Point(2-d Tensor)를 통해 쉽게 확인할 수 있게 되었다고 합니다.

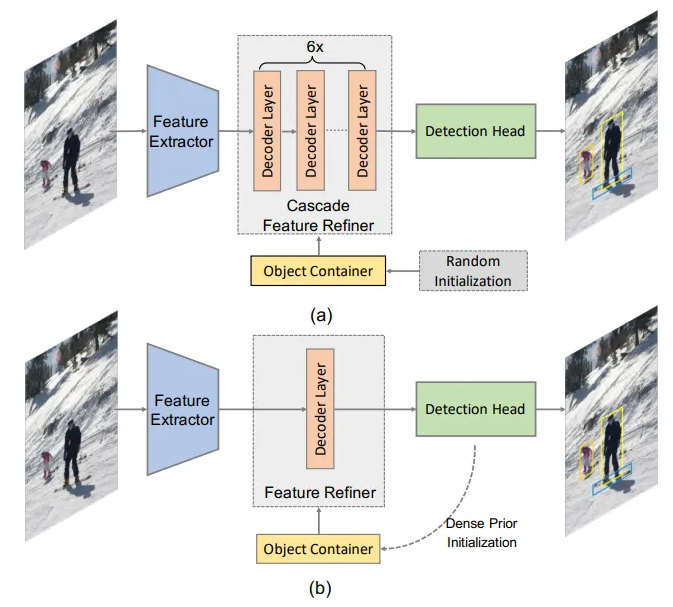
Reference Point는 랜덤으로 초기화된 Object queries에 Linear projection을 통하여 생성(a 그림)됩니다.
아래 그림은 Reference Point가 수렴하는 과정을 나타냅니다. Reference Point는 이미지 내에 균등하게 분포되어 전체 이미지 영역에 위치합니다. Reference Point의 학습 과정을 관찰한 후, 이제는 Reference Point의 초기화에 대한 방법을 연구합니다.

이어서, Reference Point를 여러 방법으로 초기화하고 cascade (6개의 Decoder Layer) 모델과 non-cascade (1개의 Decoder Layer) 모델에 각각 학습했을 때, 서로 다른 양상을 보였다고 합니다. Cascade 모델의 경우, 어떤 초기화를 적용해도 최종적으로 비슷한 성능을 보였지만, non-cascade에서는 초기화 방법에 따라 성능이 많이 변했는데, cascade에서는 Layer를 통과하며 이들의 간극을 줄이지만, non-cascade는 그러한 과정이 없기 때문에 더 큰 영향을 받는다고 합니다.

저자들은 Reference Point의 시작점을 Anchor Based 모델들의 Anchor라고 판단한 듯 합니다. 그래서 Reference Point를 Anchor points로써 다루는 방법을 고려했습니다. 따라서 RPN을 통해 Region Proposals를 생성하여, class에 무관한 후보군들을 제공합니다. RPN layer는 Encoder의 Dense feature에 추가되었으며, encoder의 feature를 공유하고, 객체감지 여부와 offset을 예측합니다.
Reference Point는 위의 방법으로 구할 수 있지만, 256-d Object Queries는 어떻게 초기값을 설정할 수 있을까요? 이 문제는 encoder feature maps에서 256-d tensor를 추출함으로써 해결했습니다. ( Archtecture 사진 (c) 부분 )
Efficient DETR
Efficient DETR은 Dense와 Sparse 두 개의 part로 나뉘어져 있습니다.
Dense Part: 위에서 언급한 것처럼, Dense Part는 Backbone, Encoder, Detection head로 구성됩니다. 2-stage Deformable DETR을 따를 때, MultiScale Feature maps의 각 위치에 대해 Anchor가 생성됩니다.
Sparse Part: Dense Part의 출력은 Encoder Feature 크기를 가집니다. Feature 중 일부를 Object Score에 따라 선택합니다. Score가 가장 큰 K개의 Proposals를 Reference Point로 선택합니다.
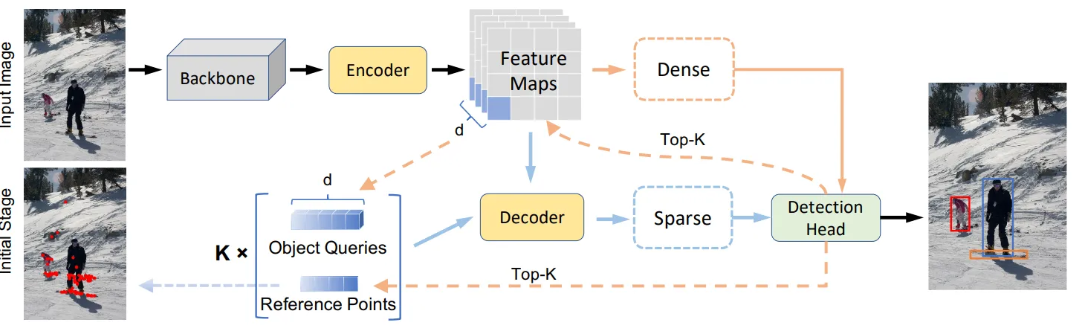
Efficient DETR의 과정을 그림으로 표현하면 위 그림과 같습니다. 이 그림의 내용을 좀 더 풀어서 설명하겠습니다.
1. Backbone, Encoder : 입력 이미지에 대해 Feature Maps를 추출합니다.
2. Dense : Dense Part는 Feature maps를 사용하여 모든 위치에서 객체 여부를 평가합니다. 이 단계에서 Detection Head를 통해 Anchor를 생성하고, 각 Anchor에 대해 Score와 Offset을 예측합니다.
3. Top-K : Dense Part에서 나온 결과 중 가장 높은 Score를 가진 K개의 Anchor가 선택됩니다.
4. Object Containers : 선택된 Top-K개에 대해 Encoder Feature Maps로부터 Object Queries를 추출합니다. Reference Points는 Detection Head로부터 가져오게 됩니다.
5. Decoder : Decoder에서는 Feature Maps와 Object Containers에 대해 Cross Attention 연산을 수행합니다.
6. Sparse : Decoder의 결과값을 전달 받아 Dense Part 보다 정밀한 객체 탐지를 수행합니다.
마치며
Panoptic SegFormer에서 마무리 글로 적은 내용처럼 아마도 DEER에서 Locatioin Head를 통해 Encoder의 Feature Maps로부터 Reference Points를 얻는 것에 영감을 받은 논문 중 하나 인듯 싶습니다.
DEER를 구현하고 학습을 진행하며, 크고 작은 문제점들이 많이 발생했었는데요. 정리 해보고 충분한 분량이 나온다면 이 부분에 대해 글을 작성하도록 하겠습니다.
'Machine Learning > Image' 카테고리의 다른 글
| Document Attention Networks (DAN) (0) | 2024.12.19 |
|---|---|
| DBNet - Real-time Scene Text Detection with Differentiable Binarization (0) | 2024.10.16 |
| Panoptic SegFormer (0) | 2024.10.07 |
| Conditional-DETR : for Fast Training Convergence (1) | 2024.09.25 |
| DEER: Detection-agnostic End-to-End Recognizer for Scene Text Spotting (4) | 2024.07.23 |